Variational AutoEncoders (VAE) with PyTorch
Download the jupyter notebook and run this blog post yourself!
Motivation
Imagine that we have a large, high-dimensional dataset. For example, imagine we have a dataset consisting of thousands of images. Each image is made up of hundreds of pixels, so each data point has hundreds of dimensions. The manifold hypothesis states that real-world high-dimensional data actually consists of low-dimensional data that is embedded in the high-dimensional space. This means that, while the actual data itself might have hundreds of dimensions, the underlying structure of the data can be sufficiently described using only a few dimensions.
This is the motivation behind dimensionality reduction techniques, which try to take high-dimensional data and project it onto a lower-dimensional surface. For humans who visualize most things in 2D (or sometimes 3D), this usually means projecting the data onto a 2D surface. Examples of dimensionality reduction techniques include principal component analysis (PCA) and t-SNE. Chris Olah’s blog has a great post reviewing some dimensionality reduction techniques applied to the MNIST dataset.
Neural networks are often used in the supervised learning context, where data consists of pairs $(x, y)$ and the network learns a function $f:X \to Y$. This context applies to both regression (where $y$ is a continuous function of $x$) and classification (where $y$ is a discrete label for $x$). However, neural networks have shown considerable power in the unsupervised learning context, where data just consists of points $x$. There are no “targets” or “labels” $y$. Instead, the goal is to learn and understand the structure of the data. In the case of dimensionality reduction, the goal is to find a low-dimensional representation of the data.
Autoencoders
Autoencoders are a special kind of neural network used to perform dimensionality reduction. We can think of autoencoders as being composed of two networks, an encoder $e$ and a decoder $d$.
The encoder learns a non-linear transformation $e:X \to Z$ that projects the data from the original high-dimensional input space $X$ to a lower-dimensional latent space $Z$. We call $z = e(x)$ a latent vector. A latent vector is a low-dimensional representation of a data point that contains information about $x$. The transformation $e$ should have certain properties, like similar values of $x$ should have similar latent vectors (and dissimilar values of $x$ should have dissimilar latent vectors).
A decoder learns a non-linear transformation $d: Z \to X$ that projects the latent vectors back into the original high-dimensional input space $X$. This transformation should take the latent vector $z = e(x)$ and reconstruct the original input data $\hat{x} = d(z) = d(e(x))$.
An autoencoder is just the composition of the encoder and the decoder $f(x) = d(e(x))$. The autoencoder is trained to minimize the difference between the input $x$ and the reconstruction $\hat{x}$ using a kind of reconstruction loss. Because the autoencoder is trained as a whole (we say it’s trained “end-to-end”), we simultaneosly optimize the encoder and the decoder.
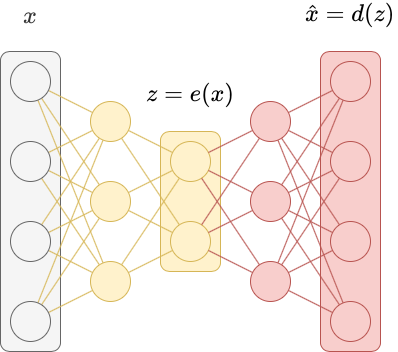
Below is an implementation of an autoencoder written in PyTorch. We apply it to the MNIST dataset.
import torch; torch.manual_seed(0)
import torch.nn as nn
import torch.nn.functional as F
import torch.utils
import torch.distributions
import torchvision
import numpy as np
import matplotlib.pyplot as plt; plt.rcParams['figure.dpi'] = 200
device = 'cuda' if torch.cuda.is_available() else 'cpu'
Below we write the Encoder class by sublcassing torch.nn.Module, which lets us define the __init__ method storing layers as an attribute, and a forward method describing the forward pass of the network.
class Encoder(nn.Module):
def __init__(self, latent_dims):
super(Encoder, self).__init__()
self.linear1 = nn.Linear(784, 512)
self.linear2 = nn.Linear(512, latent_dims)
def forward(self, x):
x = torch.flatten(x, start_dim=1)
x = F.relu(self.linear1(x))
return self.linear2(x)
We do something similar for the Decoder class, ensuring we reshape the output.
class Decoder(nn.Module):
def __init__(self, latent_dims):
super(Decoder, self).__init__()
self.linear1 = nn.Linear(latent_dims, 512)
self.linear2 = nn.Linear(512, 784)
def forward(self, z):
z = F.relu(self.linear1(z))
z = torch.sigmoid(self.linear2(z))
return z.reshape((-1, 1, 28, 28))
FInally, we write an Autoencoder class that combines these two. Note that we could have easily written this entire autoencoder as a single neural network, but splitting them in two makes it conceptually clearer.
class Autoencoder(nn.Module):
def __init__(self, latent_dims):
super(Autoencoder, self).__init__()
self.encoder = Encoder(latent_dims)
self.decoder = Decoder(latent_dims)
def forward(self, x):
z = self.encoder(x)
return self.decoder(z)
Next, we will write some code to train the autoencoder on the MNIST dataset.
def train(autoencoder, data, epochs=20):
opt = torch.optim.Adam(autoencoder.parameters())
for epoch in range(epochs):
for x, y in data:
x = x.to(device) # GPU
opt.zero_grad()
x_hat = autoencoder(x)
loss = ((x - x_hat)**2).sum()
loss.backward()
opt.step()
return autoencoder
latent_dims = 2
autoencoder = Autoencoder(latent_dims).to(device) # GPU
data = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data',
transform=torchvision.transforms.ToTensor(),
download=True),
batch_size=128,
shuffle=True)
autoencoder = train(autoencoder, data)
What should we look at once we’ve trained an autoencoder? I think that the following things are useful:
- Look at the latent space. If the latent space is 2-dimensional, then we can transform a batch of inputs $x$ using the encoder and make a scatterplot of the output vectors. Since we also have access to labels for MNIST, we can colour code the outputs to see what they look like.
- Sample the latent space to produce output. If the latent space is 2-dimensional, we can sample latent vectors $z$ from the latent space over a uniform grid and plot the decoded latent vectors on a grid.
def plot_latent(autoencoder, data, num_batches=100):
for i, (x, y) in enumerate(data):
z = autoencoder.encoder(x.to(device))
z = z.to('cpu').detach().numpy()
plt.scatter(z[:, 0], z[:, 1], c=y, cmap='tab10')
if i > num_batches:
plt.colorbar()
break
plot_latent(autoencoder, data)
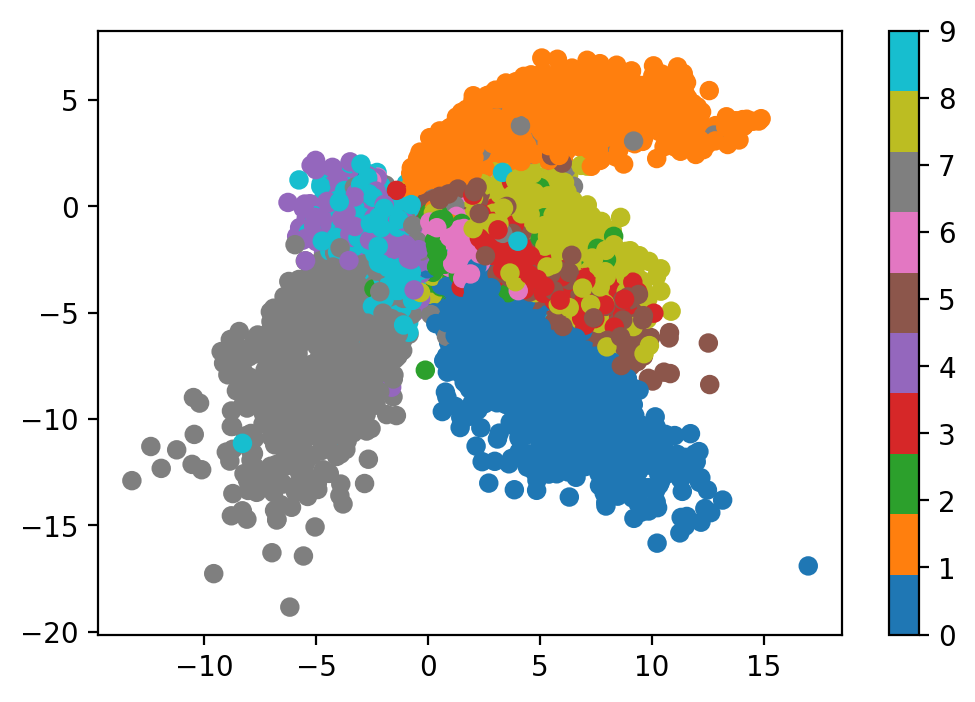
The resulting latent vectors cluster similar digits together. We can also sample uniformly from the latent space and see how the decoder reconstructs inputs from arbitrary latent vectors.
def plot_reconstructed(autoencoder, r0=(-5, 10), r1=(-10, 5), n=12):
w = 28
img = np.zeros((n*w, n*w))
for i, y in enumerate(np.linspace(*r1, n)):
for j, x in enumerate(np.linspace(*r0, n)):
z = torch.Tensor([[x, y]]).to(device)
x_hat = autoencoder.decoder(z)
x_hat = x_hat.reshape(28, 28).to('cpu').detach().numpy()
img[(n-1-i)*w:(n-1-i+1)*w, j*w:(j+1)*w] = x_hat
plt.imshow(img, extent=[*r0, *r1])
plot_reconstructed(autoencoder)
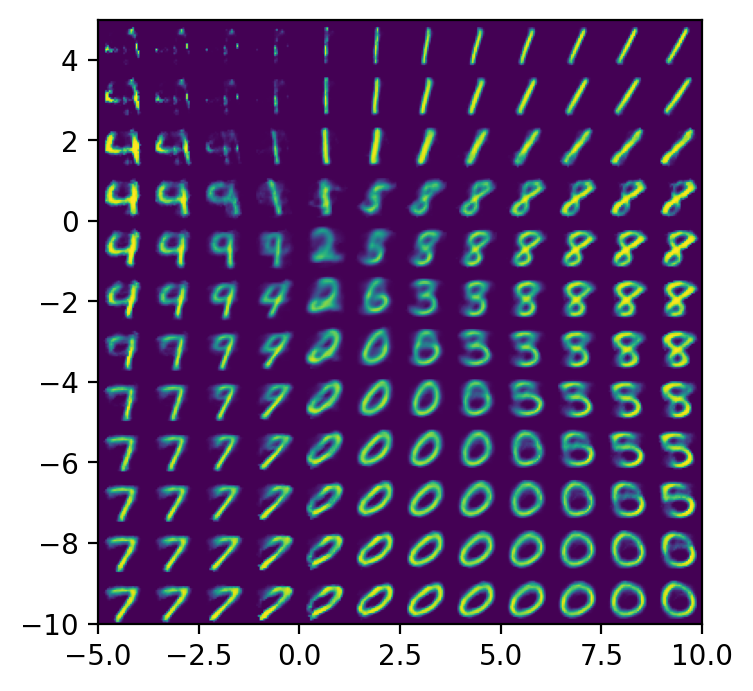
We intentionally plot the reconstructed latent vectors using approximately the same range of values taken on by the actual latent vectors. We can see that the reconstructed latent vectors look like digits, and the kind of digit corresponds to the location of the latent vector in the latent space.
You may have noticed that there are “gaps” in the latent space, where data is never mapped to. This becomes a problem when we try to use autoencoders as generative models. The goal of generative models is to take a data set $X$ and produce more data points from the same distribution that $X$ is drawn from. For autoencoders, this means sampling latent vectors $z \sim Z$ and then decoding the latent vectors to produce images. If we sample a latent vector from a region in the latent space that was never seen by the decoder during training, the output might not make any sense at all. We see this in the top left corner of the plot_reconstructed output, which is empty in the latent space, and the corresponding decoded digit does not match any existing digits.
Variational Autoencoders
The only constraint on the latent vector representation for traditional autoencoders is that latent vectors should be easily decodable back into the original image. As a result, the latent space $Z$ can become disjoint and non-continuous. Variational autoencoders try to solve this problem.
In traditional autoencoders, inputs are mapped deterministically to a latent vector $z = e(x)$. In variational autoencoders, inputs are mapped to a probability distribution over latent vectors, and a latent vector is then sampled from that distribution. The decoder becomes more robust at decoding latent vectors as a result.
Specifically, instead of mapping the input $x$ to a latent vector $z = e(x)$, we map it instead to a mean vector $\mu(x)$ and a vector of standard deviations $\sigma(x)$. These parametrize a diagonal Gaussian distribution $\mathcal{N}(\mu, \sigma)$, from which we then sample a latent vector $z \sim \mathcal{N}(\mu, \sigma)$.
This is generally accomplished by replacing the last layer of a traditional autoencoder with two layers, each of which output $\mu(x)$ and $\sigma(x)$. An exponential activation is often added to $\sigma(x)$ to ensure the result is positive.
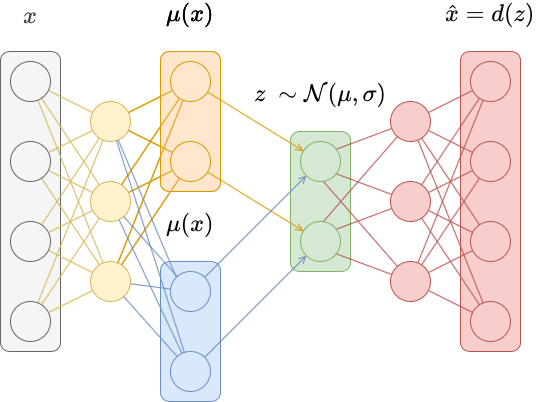
However, this does not completely solve the problem. There may still be gaps in the latent space because the outputted means may be significantly different and the standard deviations may be small. To reduce that, we add an auxillary loss that penalizes the distribution $p(z \mid x)$ for being too far from the standard normal distribution $\mathcal{N}(0, 1)$. This penalty term is the KL divergence between $p(z \mid x)$ and $\mathcal{N}(0, 1)$, which is given by \(\mathbb{KL}\left( \mathcal{N}(\mu, \sigma) \parallel \mathcal{N}(0, 1) \right) = \sum_{x \in X} \left( \sigma^2 + \mu^2 - \log \sigma - \frac{1}{2} \right)\)
This expression applies to two univariate Gaussian distributions (the full expression for two arbitrary univariate Gaussians is derived in this math.stackexchange post). Extending it to our diagonal Gaussian distributions is not difficult; we simply sum the KL divergence for each dimension.
This loss is useful for two reasons. First, we cannot train the encoder network by gradient descent without it, since gradients cannot flow through sampling (which is a non-differentiable operation). Second, by penalizing the KL divergence in this manner, we can encourage the latent vectors to occupy a more centralized and uniform location. In essence, we force the encoder to find latent vectors that approximately follow a standard Gaussian distribution that the decoder can then effectively decode.
To implement this, we do not need to change the Decoder class. We only need to change the Encoder class to produce $\mu(x)$ and $\sigma(x)$, and then use these to sample a latent vector. We also use this class to keep track of the KL divergence loss term.
class VariationalEncoder(nn.Module):
def __init__(self, latent_dims):
super(VariationalEncoder, self).__init__()
self.linear1 = nn.Linear(784, 512)
self.linear2 = nn.Linear(512, latent_dims)
self.linear3 = nn.Linear(512, latent_dims)
self.N = torch.distributions.Normal(0, 1)
self.N.loc = self.N.loc.cuda() # hack to get sampling on the GPU
self.N.scale = self.N.scale.cuda()
self.kl = 0
def forward(self, x):
x = torch.flatten(x, start_dim=1)
x = F.relu(self.linear1(x))
mu = self.linear2(x)
sigma = torch.exp(self.linear3(x))
z = mu + sigma*self.N.sample(mu.shape)
self.kl = (sigma**2 + mu**2 - torch.log(sigma) - 1/2).sum()
return z
The autoencoder class changes a single line of code, swappig out an Encoder for a VariationalEncoder.
class VariationalAutoencoder(nn.Module):
def __init__(self, latent_dims):
super(VariationalAutoencoder, self).__init__()
self.encoder = VariationalEncoder(latent_dims)
self.decoder = Decoder(latent_dims)
def forward(self, x):
z = self.encoder(x)
return self.decoder(z)
In order to train the variational autoencoder, we only need to add the auxillary loss in our training algorithm.
The following code is essentially copy-and-pasted from above, with a single term added added to the loss (autoencoder.encoder.kl).
def train(autoencoder, data, epochs=20):
opt = torch.optim.Adam(autoencoder.parameters())
for epoch in range(epochs):
for x, y in data:
x = x.to(device) # GPU
opt.zero_grad()
x_hat = autoencoder(x)
loss = ((x - x_hat)**2).sum() + autoencoder.encoder.kl
loss.backward()
opt.step()
return autoencoder
vae = VariationalAutoencoder(latent_dims).to(device) # GPU
vae = train(vae, data)
Let’s plot the latent vector representations of a few batches of data.
plot_latent(vae, data)
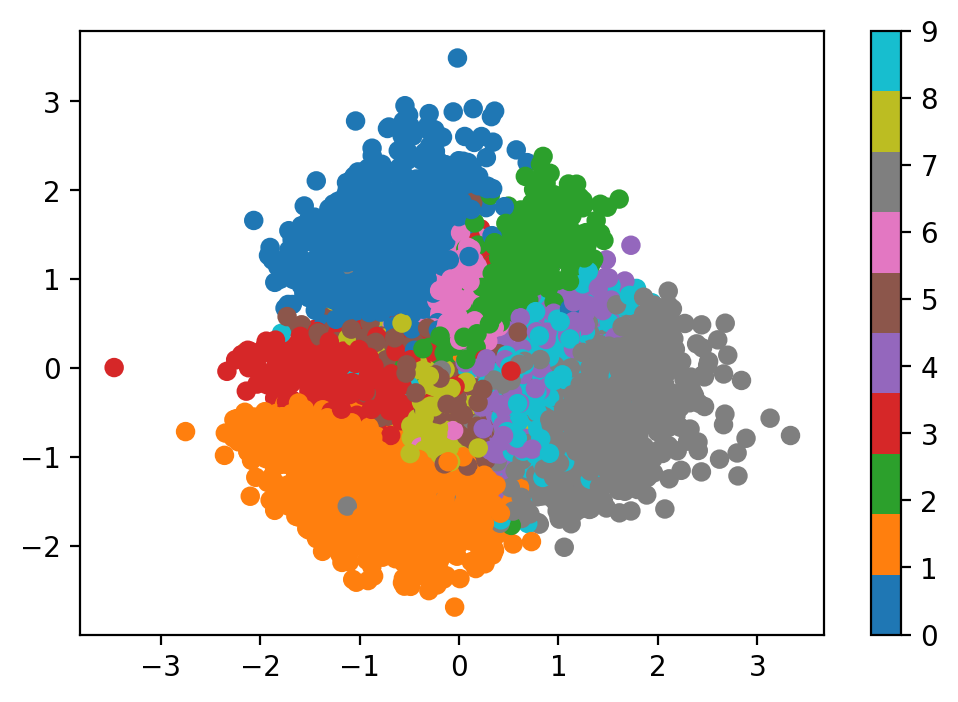
We can see that, compared to the traditional autoencoder, the range of values for latent vectors is much smaller, and more centralized. The distribution overall of $p(z \mid x)$ appears to be much closer to a Gaussian distribution.
Let’s also look at the reconstructed digits from the latent space:
plot_reconstructed(vae, r0=(-3, 3), r1=(-3, 3))
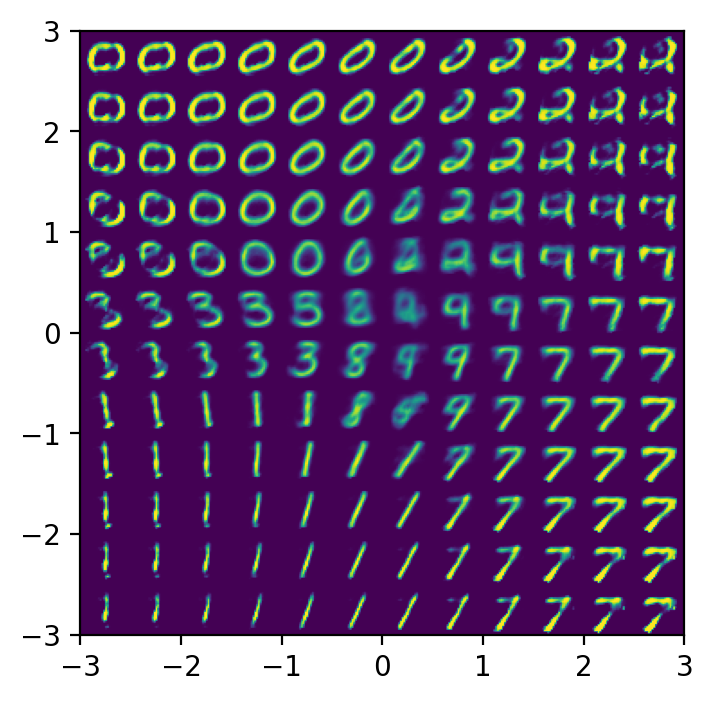
Conclusions
Variational autoencoders produce a latent space $Z$ that is more compact and smooth than that learned by traditional autoencoders. This lets us randomly sample points $z \sim Z$ and produce corresponding reconstructions $\hat{x} = d(z)$ that form realistic digits, unlike traditional autoencoders.
Extra Fun
One final thing that I wanted to try out was interpolation. Given two inputs $x_1$ and $x_2$, and their corresponding latent vectors $z_1$ and $z_2$, we can interpolate between them by decoding latent vectors between $x_1$ and $x_2$.
The following code produces a row of images showing the interpolation between digits.
def interpolate(autoencoder, x_1, x_2, n=12):
z_1 = autoencoder.encoder(x_1)
z_2 = autoencoder.encoder(x_2)
z = torch.stack([z_1 + (z_2 - z_1)*t for t in np.linspace(0, 1, n)])
interpolate_list = autoencoder.decoder(z)
interpolate_list = interpolate_list.to('cpu').detach().numpy()
w = 28
img = np.zeros((w, n*w))
for i, x_hat in enumerate(interpolate_list):
img[:, i*w:(i+1)*w] = x_hat.reshape(28, 28)
plt.imshow(img)
plt.xticks([])
plt.yticks([])
x, y = data.__iter__().next() # hack to grab a batch
x_1 = x[y == 1][1].to(device) # find a 1
x_2 = x[y == 0][1].to(device) # find a 0
interpolate(vae, x_1, x_2, n=20)

interpolate(autoencoder, x_1, x_2, n=20)

I also wanted to write some code to generate a GIF of the transition, instead of just a row of images. The code below modifies the code above to produce a GIF.
from PIL import Image
def interpolate_gif(autoencoder, filename, x_1, x_2, n=100):
z_1 = autoencoder.encoder(x_1)
z_2 = autoencoder.encoder(x_2)
z = torch.stack([z_1 + (z_2 - z_1)*t for t in np.linspace(0, 1, n)])
interpolate_list = autoencoder.decoder(z)
interpolate_list = interpolate_list.to('cpu').detach().numpy()*255
images_list = [Image.fromarray(img.reshape(28, 28)).resize((256, 256)) for img in interpolate_list]
images_list = images_list + images_list[::-1] # loop back beginning
images_list[0].save(
f'{filename}.gif',
save_all=True,
append_images=images_list[1:],
loop=1)
interpolate_gif(vae, "vae", x_1, x_2)
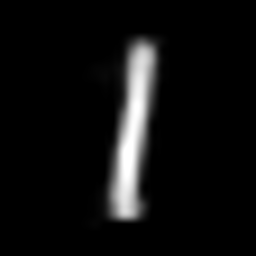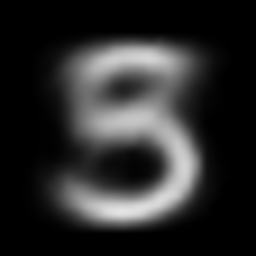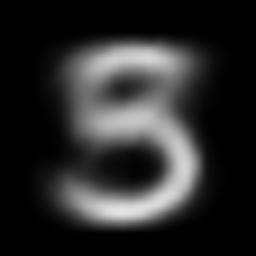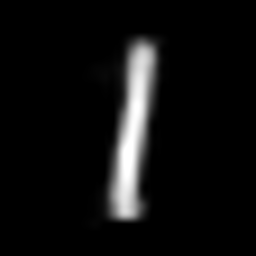
This post is inspired by these articles:
You can download the notebook here.

Leave a comment