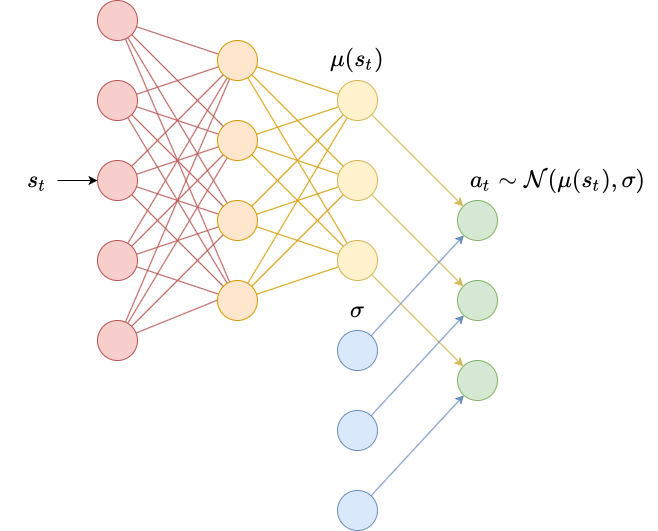
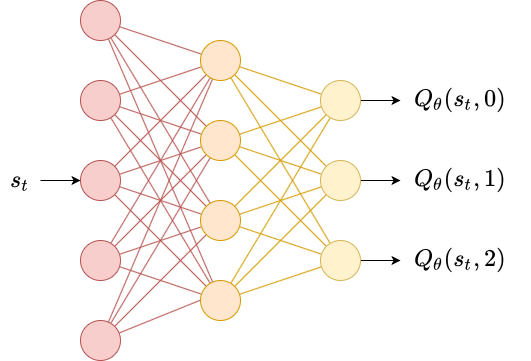
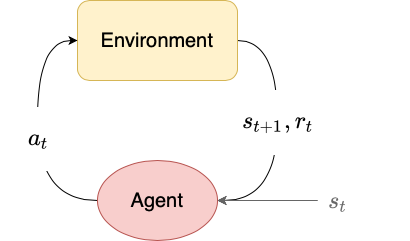
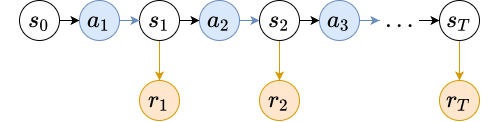
Beyond Vanilla Policy Gradients: Natural Policy Gradients, Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO)
The point of TRPO is to try to find the largest step size possible that can improve the policy, and it does this by adding a constraint on the KL divergence ...